The conundrum of content supply: more content, more bursts, more diversity, less time and resources
 Efficient content supply is critical
Efficient content supply is critical
Although easily overlooked, content supply management is critical for broadcasters and VOD publishers.
Acquired or commissioned finished content (we are not discussing live content here) is their fuel and an essential reason for their success.
From a broadcaster or VOD publisher perspective, content supply management encompasses many operations. It starts with receiving file material from many external sources and subsequently going through several transformation, verification and validation processes to end with fully validated files available for the playout or publishing processes.
The way content is programmed, published and consumed has changed drastically with the advent of OTT and SVOD.
Some content can be finished at the eleventh hour. Acquisition deals are concluded late. Time frames between content availability and rights openings are shorter and shorter. Media organisations often need to move content seamlessly between different distribution channels (e.g. from SVOD to linear) running on distinct infrastructures.
From an operational point of view, each piece of content theoretically takes the same verification effort. But in practical and economical terms, not all titles can realistically command the same effort.
Most importantly, content deals now relate to large volumes or series which are meant to be published in batches of hundreds of hours or episodes. This induces very different provisioning patterns than those linear broadcasters were dealing with before.
Historical approaches for content provisioning
Publishers and broadcasters usually have one of two principal approaches, or expectations, regarding incoming file material.
One approach is to mandate that all content be provided as files strictly complying with their own house-spec. This requires every supplier to be qualified against the applicable house spec. The technical compliance of each incoming file needs to be verified.
Although specs differences between destinations may be subtle (e.g. audio mapping or time code origin), each broadcaster or publisher destination has their own spec. In other words, despite standardisation, there is no such thing as a universal delivery format, which increases the risk of technical errors and rejections.
The other approach is to accept content under the preferred file format of each supplier. Within conventional infrastructure, this implies significant in-house facilities for processing to internal specs, sometimes complemented by external service providers. This consumes time and resources and hits capacity limits.
In the first case, significant effort and investment must be put into incoming file verification systems. In the second case, this goes to transcoding systems.
In both cases, incoming file reception volume needs to be taken care of.
Further down the line, different teams will be involved in editorial validation or quality control before content can actually be published or played out. Skilled content management teams have to deal with the many exceptions as well big and small technical or editorial issues that arise several times a day.
The fundamental industry issues hindering the efficiency of content supply chains
Why can’t delivering and provisioning content be straightforward?
Not all content suppliers are equally competent in dealing with the complexity of file formats. This complexity is the consequence of legacy standards pertaining to vintage content and large catalogues. It is compounded by continuous progress in codecs and quality.
Today, there are effectively over 100,000 possible combinations of parameters for codec families, levels, wrappers, frame rates, definitions, audio mappings and content organisation principles, to constitute any individual master or deliverable file spec (we’ve done the maths: it’s actually close to 200,000).
That’s for technicalities. Yet it’s not the whole picture.
Equally important is the fact that our industry lacks metadata and shared metadata frameworks. Either content gets delivered without any metadata or with erroneous, incomplete or ambiguous metadata (e.g. “original version with French subtitles” can mean several different things with drastically different consequences for publishers), not to mention private naming conventions.
The inevitable and lasting consequence is that the actual editorial usability of each and every content file needs to be verified. In most cases this takes place after ingest and after some processing has already happened, which means tedious multiple-party interactions and costly time and resource waste for even the simplest issue.
An unsolvable equation?
File complexity + provider diversity + content diversity + lack of metadata + blind processes + peaks and bursts: these are real-life hard facts that make achieving fast, predictable, scalable, cost-effective content supply in the non-linear age a conundrum for broadcasters and publishers, as well as for content providers.
This is not always openly recognised as an issue.
Yet, continuous investment in software for file transfer, transcoding or technical verification and related resources only deals with the issue in a limited way and will reach economical or operational capacity limits eventually.
How Nomalab’s cloud-native content management platform resolves the conundrum and brings elasticity to content supply management
Nomalab’s solution is embodied in its content-centric, collaborative and scalable content supply web platform.
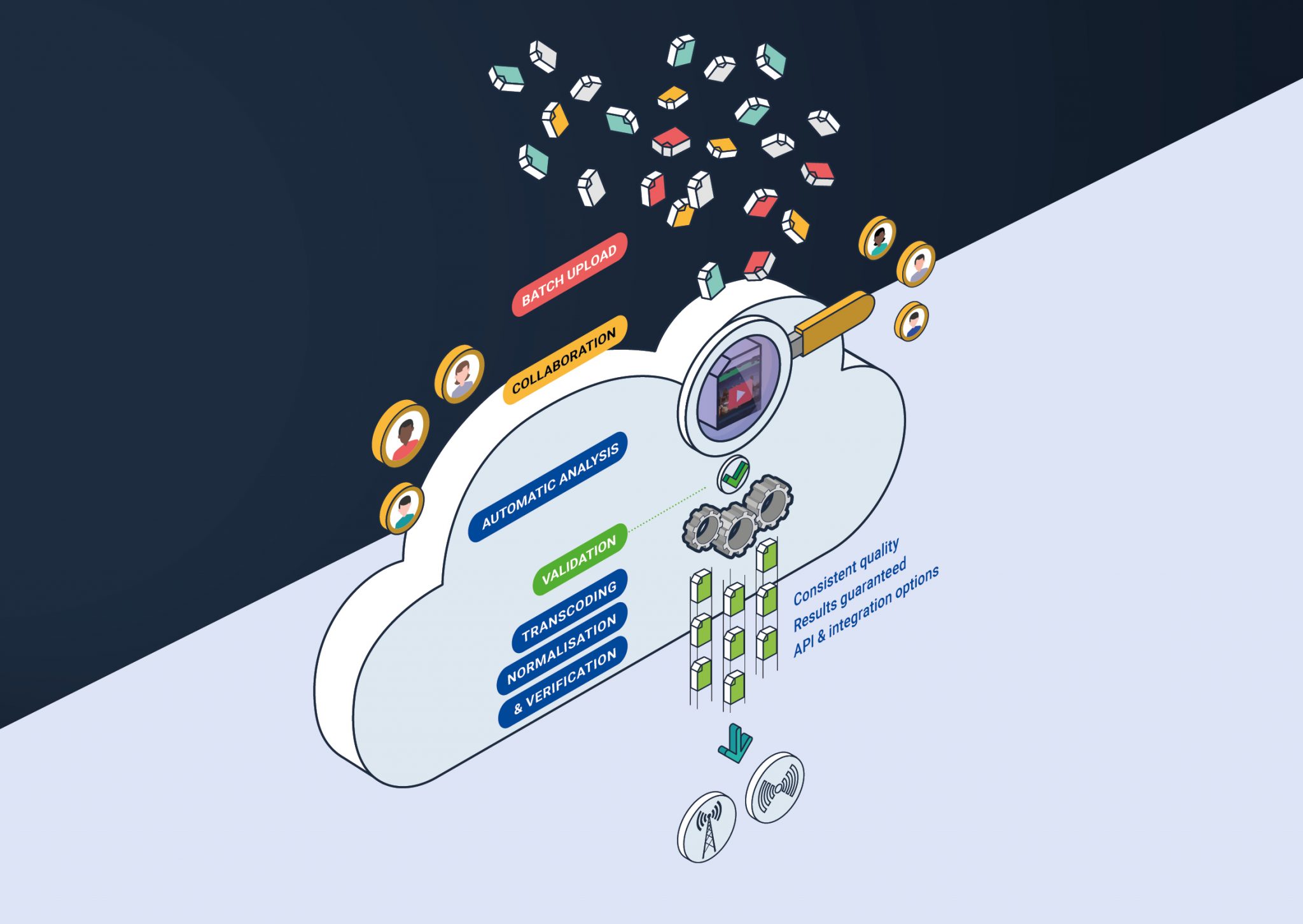
Content-centric means that once any content file is on the platform, its actual content can be played (with subtitles) at high quality with frame accuracy by any concerned party using only a web browser. This in turns enables discovery of the actual content at the earliest possible moment and without handling any file at the destination’s end.
Nomalab effectively provides a secure collaborative space between the publisher or broadcaster and each of their content providers, as well as within all concerned internal teams.
No software installation is required. Viewing, managing and collaborating around content is immediate with only a web browser.
The Nomalab platform accepts any type of video file as source and will process it into any deliverable file(s) specifications, then deliver it to its destination point, always automatically verified as fully complying with said specifications. At their end, content providers are freed from format complexity.
Content provisioning can be truly agnostic while publishers and broadcasters can rely on predictable, constant quality file deliveries into their own publishing and playout systems, with various integration options for maximum automation.
Nomalab runs its own code on its web architecture fully distributed in the AWS cloud. It is scalable without limits and has no bandwidth constraints at its end. Each job is independent from any other job; each job’s processing time is unaffected by the number of other jobs running concurrently. It takes no more time to process a full season as just one episode.
Nomalab’s SaaS model makes content provisioning immediately agnostic and elastic in all respects, whilst removing the need for investments into file reception, verification and transcoding software and hardware, thus enabling content management teams to focus on their most important tasks.
Leading French publishers and broadcasters such as 6play, Salto, M6 Group or TF1 Group already use Nomalab for agnostic and elastic content provisioning.
Jean Gaillard is president of Nomalab.
Nomalab will be at IBC, Hall 2 A36g. Book a demo here.
This is sponsored content.


